📊 Data Pipelines 101: The Ultimate Guide to Building, Deploying, and Scaling Data Workflows! 🚀
📊 Data Pipelines 101: The Ultimate Guide to Building, Deploying, and Scaling Data Workflows! 🚀
Data is the new oil, but without the right pipelines, it’s just a messy puddle. Data pipelines are the backbone of modern data-driven businesses, ensuring seamless data flow from source to destination. Whether you’re a data engineer, analyst, or tech enthusiast, this guide will walk you through types, terminologies, tools, and best practices for deploying robust data pipelines — with real-world examples!
🔍 What is a Data Pipeline?
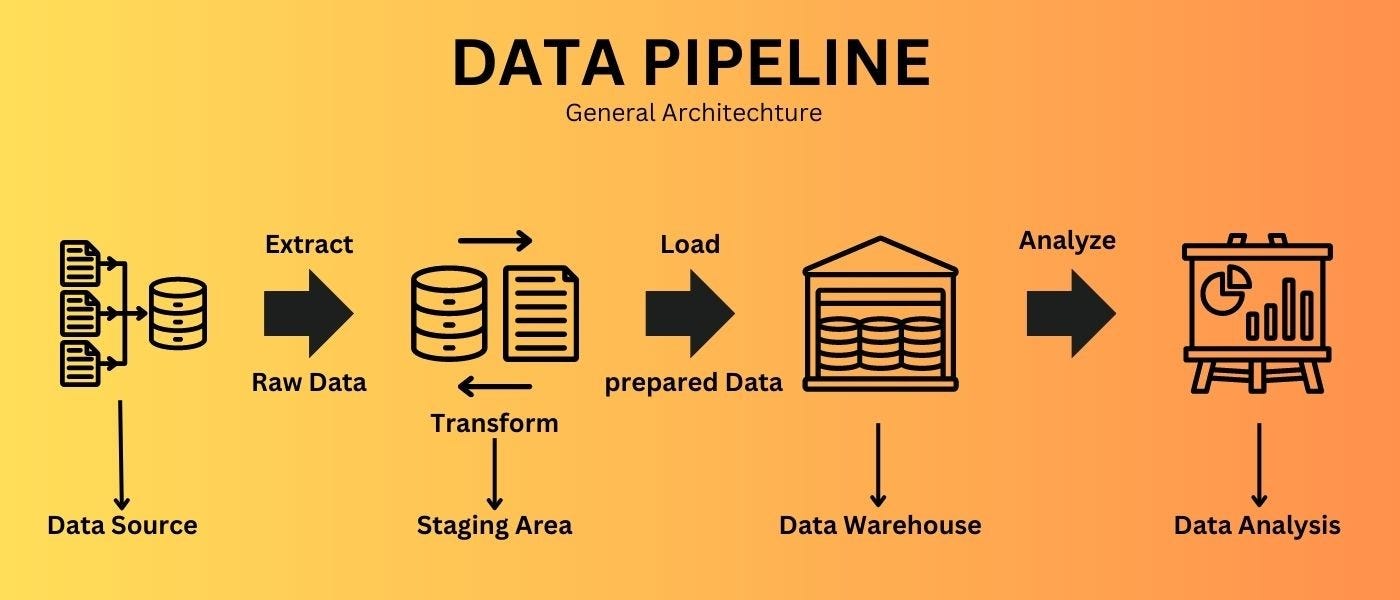
A data pipeline is a series of processes that move data from one system to another, transforming and processing it along the way. Think of it as an assembly line for data — raw data goes in, and clean, structured, actionable insights come out.
Example:
A retail company collects customer transactions (source) → processes & cleans the data (transformation) → stores it in a data warehouse (destination) → analyzes it for business insights (consumption).
🏷️ Key Terminologies in Data Pipelines

🔧 Types of Data Pipelines
1️⃣ Batch Processing Pipelines
- Processes data in scheduled chunks (hourly/daily).
- Use Case: Monthly financial reports, historical data analysis.
- Tools: Apache Airflow, Luigi, AWS Glue.
2️⃣ Streaming Pipelines
- Processes data in real-time.
- Use Case: Uber’s live ride tracking, stock market alerts.
- Tools: Apache Kafka, Apache Flink, AWS Kinesis.
3️⃣ ETL (Extract, Transform, Load)
- Transforms data before storage.
- Use Case: Cleaning customer data before loading into a CRM.
- Tools: Talend, Informatica, Apache NiFi.
4️⃣ ELT (Extract, Load, Transform)
- Loads raw data first, transforms later.
- Use Case: BigQuery/Snowflake transformations.
- Tools: dbt (Data Build Tool), Matillion.
5️⃣ Machine Learning Pipelines
- Automates ML workflows (data prep → training → deployment).
- Use Case: Netflix’s recommendation engine.
- Tools: Kubeflow, MLflow, TensorFlow Extended (TFX).
🛠️ Top Data Pipeline Tools
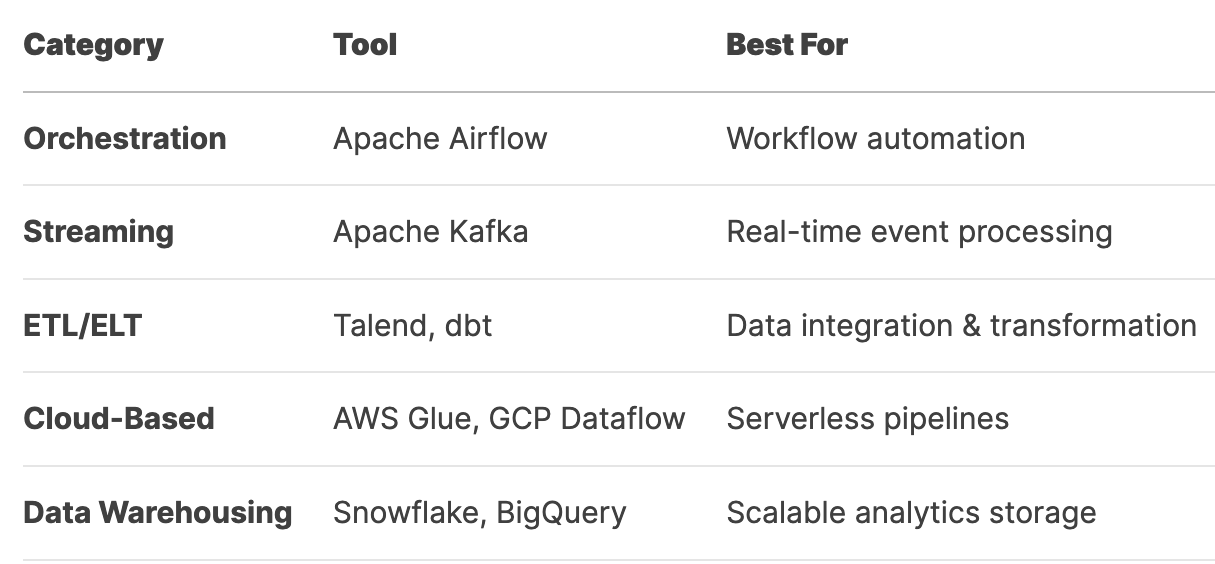
🚀 Best Deployment Strategies & Solutions
✅ 1. Cloud-Native Pipelines (Serverless)
- Pros: Auto-scaling, low maintenance.
- Example: AWS Glue (ETL) + Amazon Redshift (Warehouse).
✅ 2. Hybrid Approach (On-Prem + Cloud)
- Pros: Security + scalability.
- Example: Kafka for streaming (on-prem) → Snowflake (cloud).
✅ 3. Containerized Pipelines (Kubernetes)
- Pros: Portable, scalable.
- Example: Airflow on Kubernetes for workflow orchestration.
✅ 4. Data Mesh Architecture
- Pros: Decentralized ownership.
- Example: Domain-specific pipelines (marketing, finance).
🏆 Pro Tips for Perfect Data Pipelines
✔ Monitor & Log Everything — Use tools like Datadog or Prometheus.
✔ Ensure Idempotency — Reruns shouldn’t duplicate data.
✔ Optimize Costs — Use spot instances for batch jobs.
✔ Data Quality Checks — Validate with Great Expectations or dbt tests.
✔ Security First — Encrypt data in transit & at rest.
🌟 Final Thoughts
Data pipelines are the unsung heroes of analytics, AI, and business intelligence. Whether you’re building batch ETL jobs or real-time streaming systems, choosing the right architecture and tools is key.
🚀 Now go build something awesome!
💬 What’s your favorite data pipeline tool? Drop a comment below! 👇
#DataEngineering #ETL #BigData #DataScience #TechBlog
Comments
Post a Comment